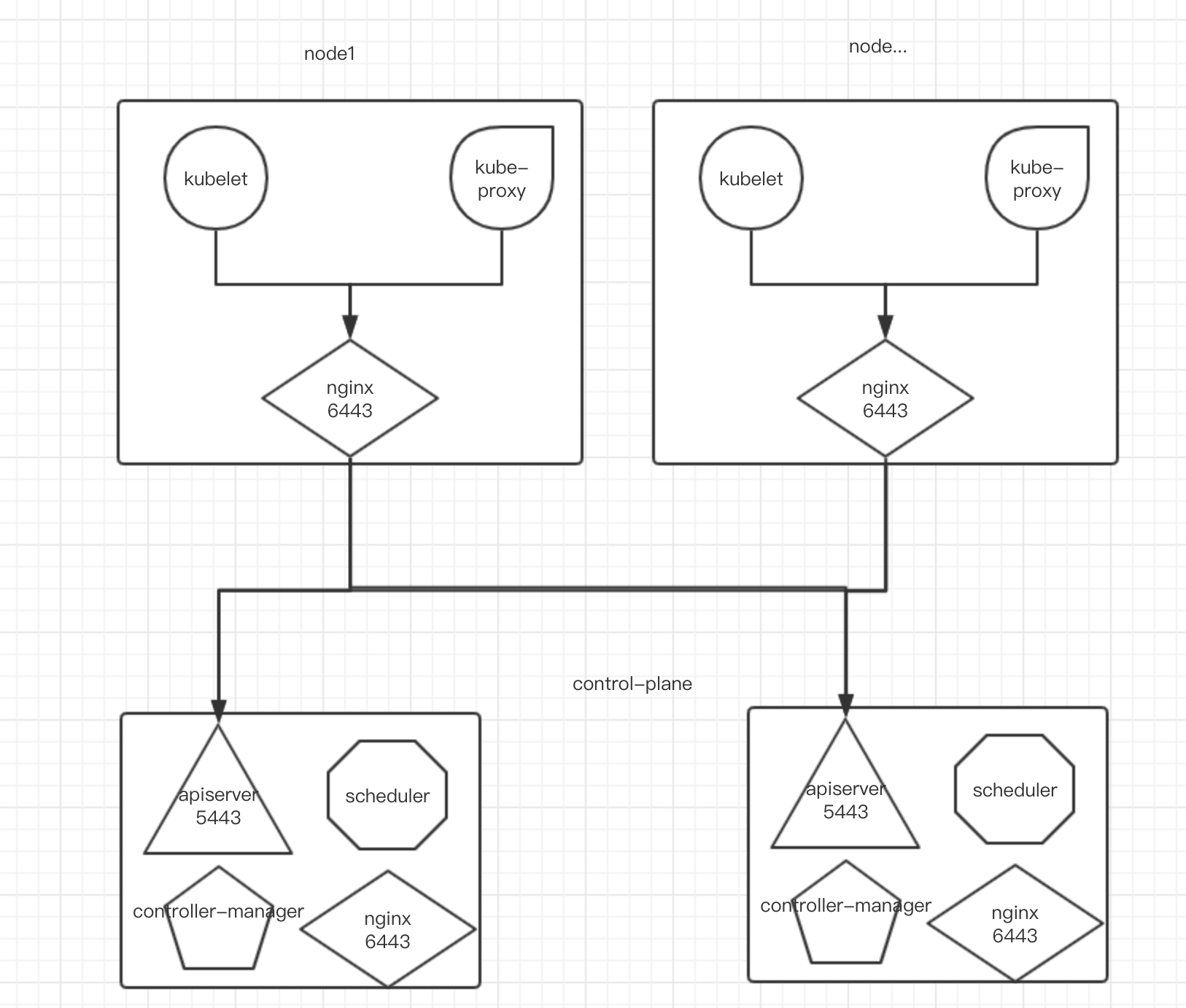
一种是深度耦合到 control plane 上,即每个 control plane 一个 etcd
另一种是使用外部的 Etcd 集群,通过在配置中指定外部集群让 apiserver 等组件连接
在测试深度耦合 control plane 方案后,发现一些比较恶心的问题;比如说开始创建第二个 control plane 时配置写错了需要重建,此时你一旦删除第二个 control plane 会导致第一个 control plane 也会失败,原因是创建第二个 control plane 时 kubeadm 已经自动完成了 etcd 的集群模式,当删除第二个 control plane 的时候由于集群可用原因会导致第一个 control plane 下的 etcd 发现节点失联从而也不提供服务;所以综合考虑到后续迁移、灾备等因素,这里选择了将 etcd 放置在外部集群中;同样也方便我以后各种折腾应对一些极端情况啥的。
4.2、部署 Etcd
确定了需要在外部部署 etcd 集群后,只需要开干就完事了;查了一下 ubuntu 官方源已经有了 etcd 安装包,但是版本比较老,测试了一下 golang 的 build 版本是 1.10;所以我还是选择了从官方 release 下载最新的版本安装;当然最后还是因为懒,我自己打了一个 deb 包… deb 包可以从这个项目 mritd/etcd-deb 下载,担心安全性的可以利用项目脚本自己打包,以下是安装过程:
# [cluster] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://172.16.10.21:2380" # if you use different ETCD_NAME (e.g. test), set ETCD_INITIAL_CLUSTER value for this name, i.e. "test=http://..." ETCD_INITIAL_CLUSTER="etcd1=https://172.16.10.21:2380,etcd2=https://172.16.10.22:2380,etcd3=https://172.16.10.23:2380" ETCD_INITIAL_CLUSTER_STATE="new" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_ADVERTISE_CLIENT_URLS="https://172.16.10.21:2379" #ETCD_DISCOVERY="" #ETCD_DISCOVERY_SRV="" #ETCD_DISCOVERY_FALLBACK="proxy" #ETCD_DISCOVERY_PROXY="" #ETCD_STRICT_RECONFIG_CHECK="false" ETCD_AUTO_COMPACTION_RETENTION="24"
https://172.16.10.21:2379 is healthy: successfully committed proposal: took = 16.632246ms https://172.16.10.23:2379 is healthy: successfully committed proposal: took = 21.122603ms https://172.16.10.22:2379 is healthy: successfully committed proposal: took = 22.592005ms
五、部署 Kubernetes
5.1、安装 kueadm
安装 kubeadm 没什么好说的,国内被墙用阿里的源既可
1 2 3 4 5 6 7 8 9
apt-get install -y apt-transport-https curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main EOF apt update
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
所有 control plane 启动完成后应当通过在每个节点上运行 kubectl get cs 验证各个组件运行状态
1 2 3 4 5 6 7 8 9 10 11 12 13
k2.node ➜ kubectl get cs NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-1 Healthy {"health":"true"} etcd-0 Healthy {"health":"true"} etcd-2 Healthy {"health":"true"}
# 查看证书过期时间 k1.node ➜ kubeadm alpha certs check-expiration [check-expiration] Reading configuration from the cluster... [check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED admin.conf Jan 11, 2021 10:06 UTC 364d no apiserver Jan 11, 2021 10:06 UTC 364d ca no apiserver-kubelet-client Jan 11, 2021 10:06 UTC 364d ca no controller-manager.conf Jan 11, 2021 10:06 UTC 364d no front-proxy-client Jan 11, 2021 10:06 UTC 364d front-proxy-ca no scheduler.conf Jan 11, 2021 10:06 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED ca Jan 09, 2030 10:06 UTC 9y no front-proxy-ca Jan 09, 2030 10:06 UTC 9y no
# 续签证书 k1.node ➜ kubeadm alpha certs renew all [renew] Reading configuration from the cluster... [renew] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
certificate embedded in the kubeconfig file for the admin to use and for kubeadm itself renewed certificate for serving the Kubernetes API renewed certificate for the API server to connect to kubelet renewed certificate embedded in the kubeconfig file for the controller manager to use renewed certificate for the front proxy client renewed certificate embedded in the kubeconfig file for the scheduler manager to use renewed
# 列出 token k1.node ➜ kubeadm token list TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS r4t3l3.14mmuivm7xbtaeoj 22h 2020-01-13T18:06:54+08:00 authentication,signing <none> system:bootstrappers:kubeadm:default-node-token zady4i.57f9i2o6zl9vf9hy 45m 2020-01-12T20:06:53+08:00 <none> Proxy for managing TTL for the kubeadm-certs secret <none>
# 创建新 token k1.node ➜ kubeadm token create --print-join-command W0112 19:21:15.174765 26626 validation.go:28] Cannot validate kube-proxy config - no validator is available W0112 19:21:15.174836 26626 validation.go:28] Cannot validate kubelet config - no validator is available kubeadm join 127.0.0.1:6443 --token 2dz4dc.mobzgjbvu0bkxz7j --discovery-token-ca-cert-hash sha256:06f49f1f29d08b797fbf04d87b9b0fd6095a4693e9b1d59c429745cfa082b31d
如果忘记了 certificate-key 可以通过一下命令重新 upload 并查看
1 2 3 4 5 6
k1.node ➜ kubeadm init --config kubeadm.yaml phase upload-certs --upload-certs W0112 19:23:06.466711 28637 validation.go:28] Cannot validate kubelet config - no validator is available W0112 19:23:06.466778 28637 validation.go:28] Cannot validate kube-proxy config - no validator is available [upload-certs] Storing the certificates in Secret "kubeadm-certs"in the "kube-system" Namespace [upload-certs] Using certificate key: 7373f829c733b46fb78f0069f90185e0f00254381641d8d5a7c5984b2cf17cd3