如何在 Filebeat 端进行日志处理
一、起因
目前某项目组日志需要做切割处理,针对日志信息进行分割并提取 k/v 放入 es 中方便查询。这种需求在传统 ELK 中应当由 logstash 组件完成,通过 gork 等操作对日志进行过滤、切割等处理。不过很尴尬的是我并不会 ruby,logstash pipeline 的一些配置我也是极其头疼,而且还不想学…更不凑巧的是我会写点 go,那么理所应当的此时的我对 filebeat 源码产生了一些想法,比如我直接在 filebeat 端完成日志处理,然后直接发 es/logstash,这样似乎更方便,而且还能分摊 logstash 的压力,我感觉这个操作并不过分😂…
二、需求
目前某项目组 java 日志格式如下:
1 | |
目前开发约定格式为日志通过 $$ 进行分割,日志格式比较简单,但是 logstash 共用(nginx 等各种日志都会往这个 logstash 输出),不想去折腾 logstash 配置的情况下,只需要让 filebeat 能够直接切割并设置好 k/v 对应既可。
三、filebeat module
module 部份只做简介,以为实际上依托 es 完成,意义不大。
当然在考虑修改 filebeat 源码后,我第一想到的是 filebeat 的 module,这个 module 在官方文档中是个很神奇的东西;通过开启一个 module 就可以对某种日志直接做处理,这种东西似乎就是我想要的;比如我写一个 “项目名” module,然后 filebeat 直接开启这个 module,这个项目的日志就直接自动处理好(听起来就很 “上流”)…
针对于自定义 module,官方给出了文档: Creating a New Filebeat Module
按照文档操作如下(假设我们的项目名为 cdm):
1 | |
创建完成后目录结构如下
1 | |
这几个文件具体作用官方文档都有详细的描述;但是根据文档描述光有这几个文件是不够的,**module 只是一个处理集合的定义,尚未包含任何处理,针对真正的处理需要继续创建 fileset,fileset 简单的理解就是针对具体的一组文件集合的处理;**例如官方 nginx module 中包含两个 fileset: access 和 error,这两个一个针对 access 日志处理一个针对 error 日志进行处理;在 fileset 中可以设置默认文件位置、处理方式。
**But… 我翻了 nginx module 的样例配置才发现,module 这个东西实质上只做定义和存储处理表达式,具体的切割处理实际上交由 es 的 Ingest Node 处理;表达式里仍需要定义 grok 等操作,而且这东西最终会编译到 go 静态文件里;**此时的我想说一句 “MMP”,本来我是不像写 grok 啥的才来折腾 filebeat,结果这个 module 折腾一圈还是要写 grok 啥的,而且这东西直接借助 es 完成导致压力回到了 es 同时每次修改还得重新编译 filebeat… 所以折腾到这我就放弃了,这已经违背了当初的目的,有兴趣的可以参考以下文档继续折腾:
四、filebeat processors
经历了 module 的失望以后,我把目光对准了 processors;processors 是 filebeat 一个强大的功能,顾名思义它可以对 filbeat 收集到的日志进行一些处理;从官方 Processors 页面可以看到其内置了大量的 processor;这些 processor 大部份都是直接对日志进行 “写” 操作,所以理论上我们自己写一个 processor 就可以 “为所欲为+为所欲为=为所欲为”。
不过不幸的是关于 processor 的开发官方并未给出文档,官方认为这是一个 high level 的东西,不过也找到了一个 issue 对其做了相关回答: How do I write a processor plugin by myself;所以最好的办法就是直接看已有 processor 的源码抄一个。
理所应当的找了一个软柿子捏: add_host_metadata,add_host_metadata processor 顾名思义在每个日志事件(以下简称为 event)中加入宿主机的信息,比如 hostname 啥的;以下为 add_host_metadata processor 的文件结构(processors 代码存储在 libbeat/processors 目录下)。
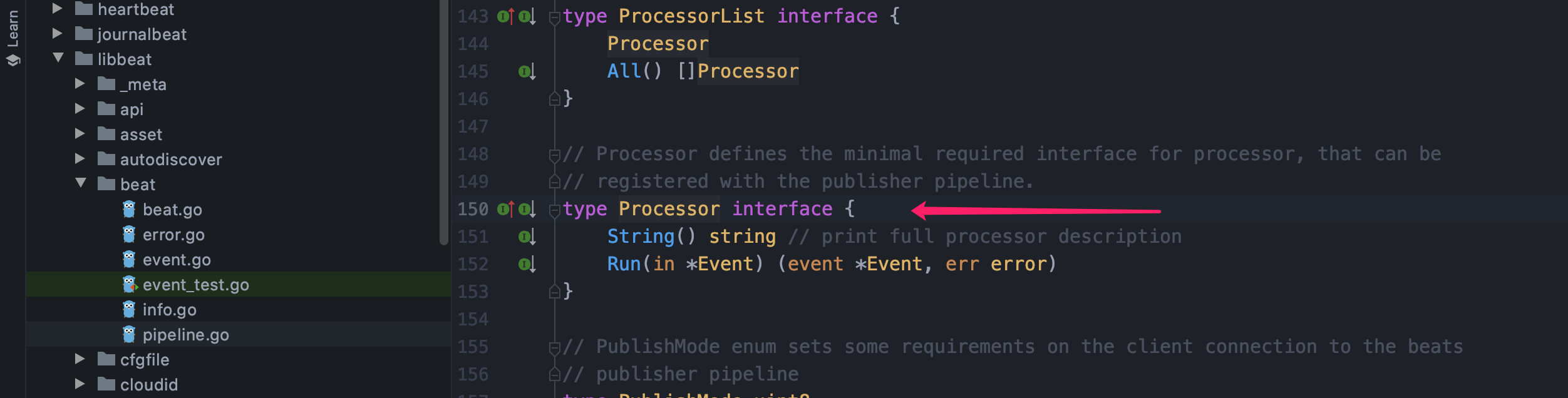
通过阅读源码和 issue 的回答可以看出,我们自定义的 processor 只需要实现 Processor interface 既可,这个接口定义如下:
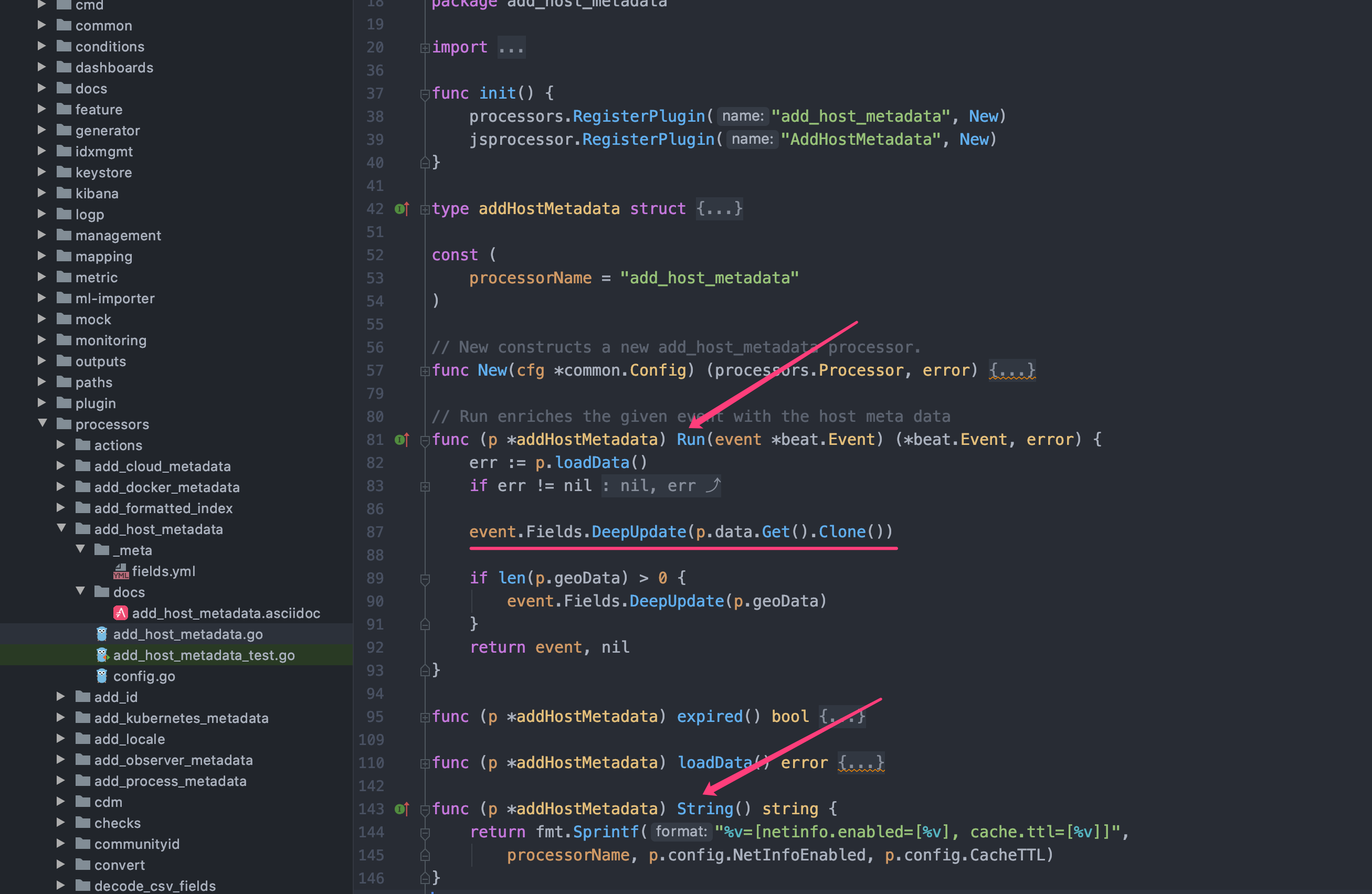
通过查看 add_host_metadata 的源码,String() string 方法只需要返回这个 processor 名称既可(可以包含必要的配置信息);而 Run(event *beat.Event) (*beat.Event, error) 方法表示在每一条日志被读取后都会转换为一个 event 对象,我们在方法内进行处理然后把 event 返回既可(其他 processor 可能也要处理)。
有了这些信息就简单得多了,毕竟作为一名合格的 CCE(Ctrl C + Ctrl V + Engineer) 抄这种操作还是很简单的,直接照猫画虎写一个就行了
config.go
1 | |
cdm.go
1 | |
写好代码以后就可以编译一个自己的 filebeat 了(开心ing)
1 | |
然后编写配置文件进行测试,日志相关字段已经成功塞到了 event 中,这样我直接发到 es 或者 logstash 就行了。
1 | |
五、script processor
在我折腾完源码以后,反思一下其实这种方式需要自己编译 filebeat,而且每次规则修改也很不方便,唯一的好处真的就是用代码可以 “为所欲为”;反过来一想 “filebeat 有没有 processor 的扩展呢?脚本热加载那种?” 答案是使用 script processor,script processor 虽然名字上是个 processor,实际上其包含了完整的 ECMA 5.1 js 规范实现;结论就是我们可以写一些 js 脚本来处理日志,然后 filebeat 每次启动后加载这些脚本既可。
script processor 的使用方式很简单,js 文件中只需要包含一个 function process(event) 方法既可,与自己用 go 实现的 processor 类似,每行日志也会形成一个 event 对象然后调用这个方法进行处理;目前 event 对象可用的 api 需要参考官方文档;**需要注意的是 script processor 目前只支持 ECMA 5.1 语法规范,超过这个范围的语法是不被支持;**实际上其根本是借助了 https://github.com/dop251/goja 这个库来实现的。同时为了方便开发调试,script processor 也增加了一些 nodejs 的兼容 module,比如 console.log 等方法是可用的;以下为 js 处理上面日志的逻辑:
1 | |
写好脚本后调整配置测试既可,如果 js 编写有问题,可以通过 console.log 来打印日志进行不断的调试
1 | |
需要注意的是目前 lang 的值只能为 javascript 和 js(官方文档写的只能是 javascript);根据代码来看后续 script processor 有可能支持其他脚本语言,个人认为主要取决于其他脚本语言有没有纯 go 实现的 runtime,如果有的话未来很有可能被整合到 script processor 中。

六、其他 processor
研究完 script processor 后我顿时对其他 processor 也产生了兴趣,随着更多的查看processor 文档,我发现其实大部份过滤分割能力已经有很多 processor 进行了实现,**其完善程度外加可扩展的 script processor 实际能力已经足矣替换掉 logstash 的日志分割过滤处理了。**比如上面的日志切割其实使用 dissect processor 实现更加简单(这个配置并不完善,只是样例):
1 | |
除此之外还有很多 processor,例如 drop_event、drop_fields、timestamp 等等,感兴趣的可以自行研究。
七、总结
基本上折腾完以后做了一个总结:
- filebeat module: 这就是个华而不实的东西,每次修改需要重新编译且扩展能力几近于零,最蛋疼的是实际逻辑通过 es 来完成;我能想到的是唯一应用场景就是官方给我们弄一些 demo 来炫耀用的,比如 nginx module;实际生产中 nginx 日志格式保持原封不动的人我相信少之又少。
- filebeat custom processor: 每次修改也需要重新编译且需要会 go 语言还有相关工具链,但是好处就是完全通过代码实现真正的为所欲为;扩展性取决于外部是否对特定位置做了可配置化,比如预留可以配置切割用正则表达式的变量等,最终取决于代码编写者(怎么为所欲为的问题)。
- filebeat script processor: 完整 ECMA 5.1 js 规范支持,代码化对日志进行为所欲为,修改不需要重新编译;普通用户我个人觉得是首选,当然同时会写 go 和 js 的就看你想用哪个了。
- filebeat other processor: 基本上实现了很多 logstash 的功能,简单用用很舒服,复杂场景还是得撸代码;但是一些特定的 processor 很实用,比如加入宿主机信息的 add_host_metadata processor 等。