Kubernetes 深度学习笔记
本文主要记录下 Kubernetes 下运行深度学习框架如 Tensorflow、Caffe2 等一些坑,纯总结性文档
一、先决条件
Kubernetes 运行深度学习应用实际上要解决的唯一问题就是 GPU 调用,以下只描述 Nvidia 相关的问题以及解决方法;要想完成 Kubernetes 对 GPU 调用,首先要满足以下条件:
- Nvidia 显卡驱动安装正确
- CUDA 安装正确
- Nvidia Docker 安装正确
关于 Nvidia 驱动和 CUDA 请自行查找安装方法,如果这两部都搞不定,那么不用继续了
还有一点需要注意: /var/lib 这个目录不能处于单独分区中,具体原因下面阐述
二、Nvidia Docker 安装
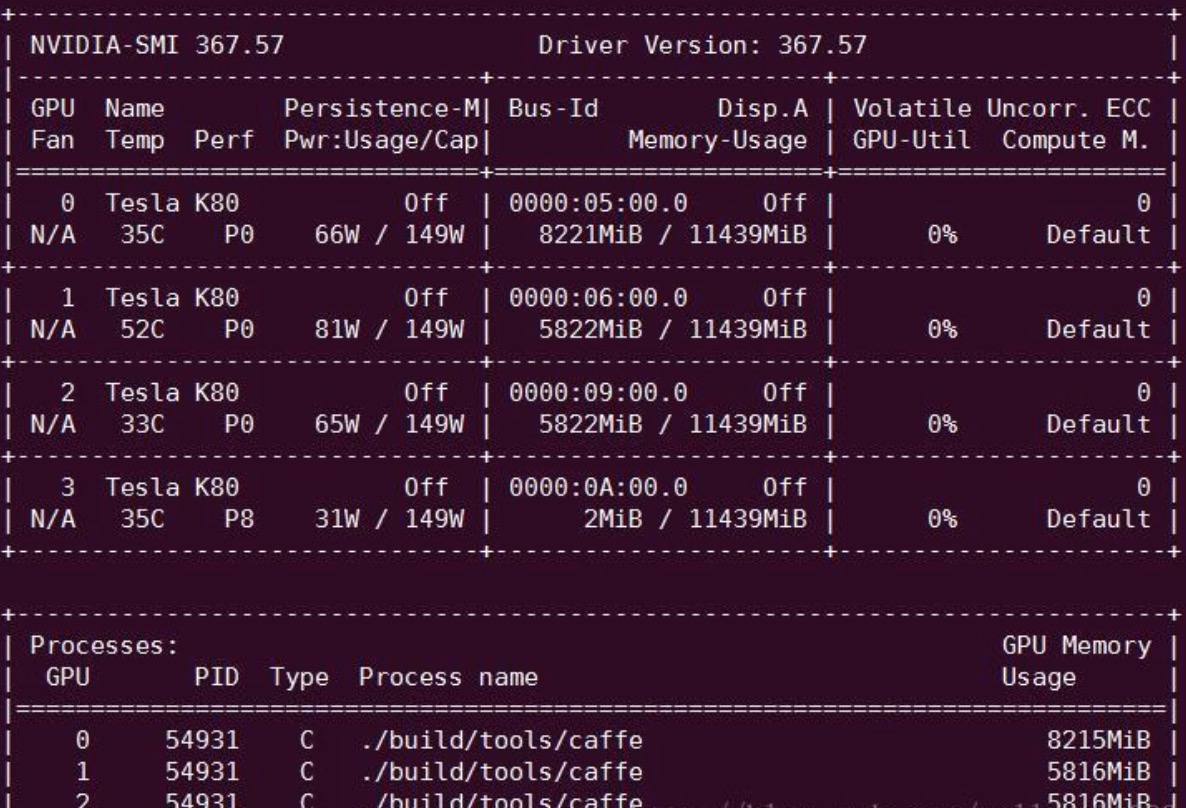
在安装 Nvidia Docker 之前,请确保 Nvidia 驱动以及 CUDA 安装成功,并且 nvidia-smi 能正确显示,如下图所示(来源于网络)
Nvidia Docker 安装极其简单,具体可参考 官方文档,安装完成后请自行按照官方文档描述进行测试,这一步一般不会出现问题
如果测试成功后,请查看 /var/lib/nvidia-docker/volumes 目录下是否有文件,如果没有,那就意味着 Nvidia Docker 并未生成相关的驱动文件成功,需要单独执行 docker volume create --driver=nvidia-docker --name=nvidia_driver_$(modinfo -F version nvidia) 以生成该文件;该命令生成的方式是将已经安装到系统的相关文件硬链接至此,所以要求 /var/lib 目录不能在单独的分区;驱动生成完成后应该会产生类似 /var/lib/nvidia-docker/volumes/nvidia_driver/375.66 的目录结构
三、Kubernetes 配置
当所有基础环境就绪后,最后需要开启 Kubernetes 对 GPU 支持;Kubernetes GPU 文档可以参考 这里,实际主要就是在 kubelet 启动时增加 --feature-gates="Accelerators=true" 参数,如下所示
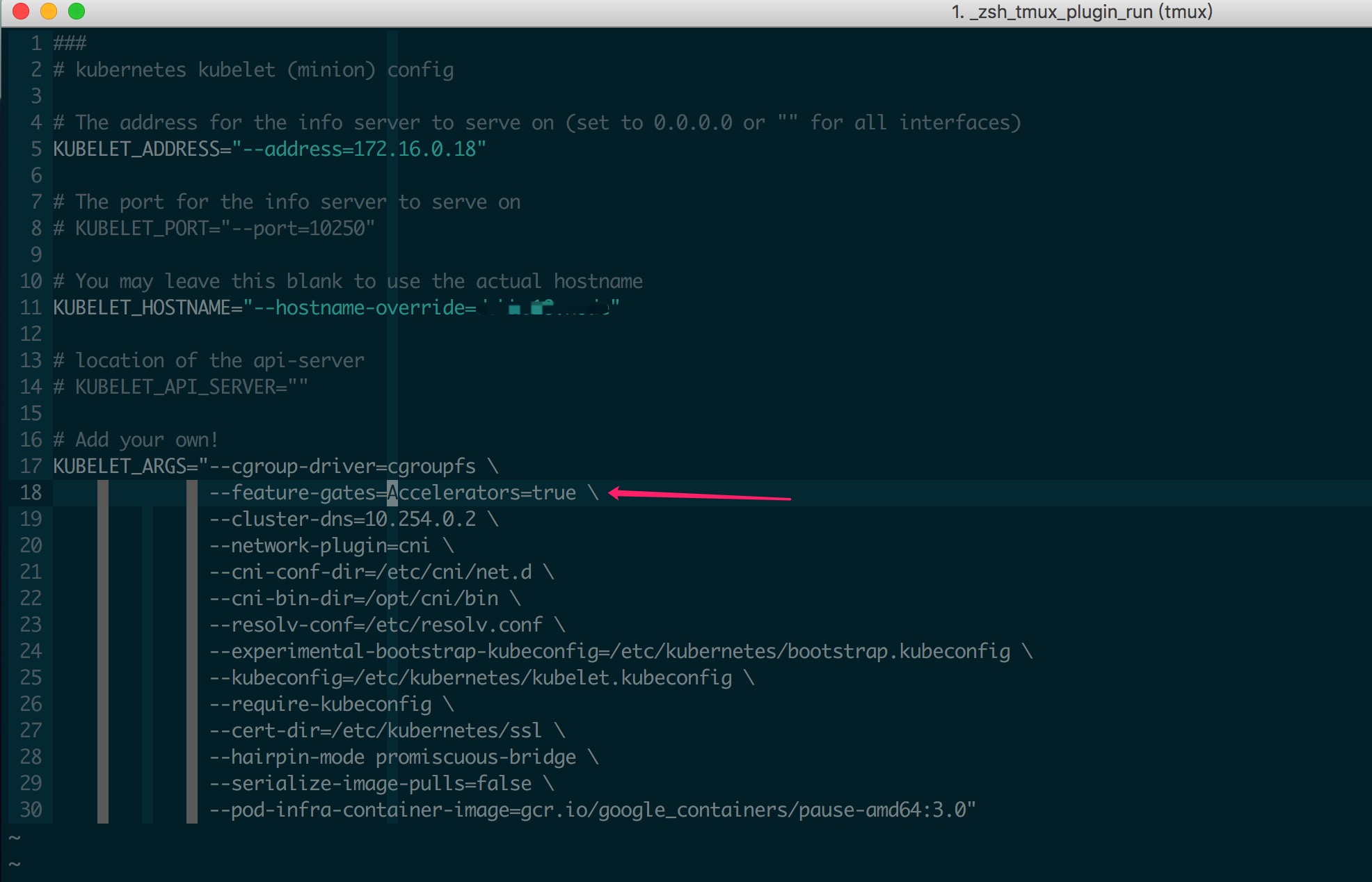
所有节点全部修改完成后重启 kubelet 即可,如果一台机器上有不同型号的显卡,同时希望 Pod 能区别使用不同的 GPU 则可以按照 官方文档 增加相应设置
四、Deployment 设置
Deployment 部署采用一个 Tensorflow 镜像作为示例,部署配置如下
1 | |
Deployment 中运行的 Pod 需要挂载对应的宿主机设备文件以及驱动文件才能正确的调用宿主机 GPU,所以一定要确保前几步生成的相关驱动文件等没问题;如果有多个 nvidia 显卡的话可能需要挂载多个 nvidia 设备
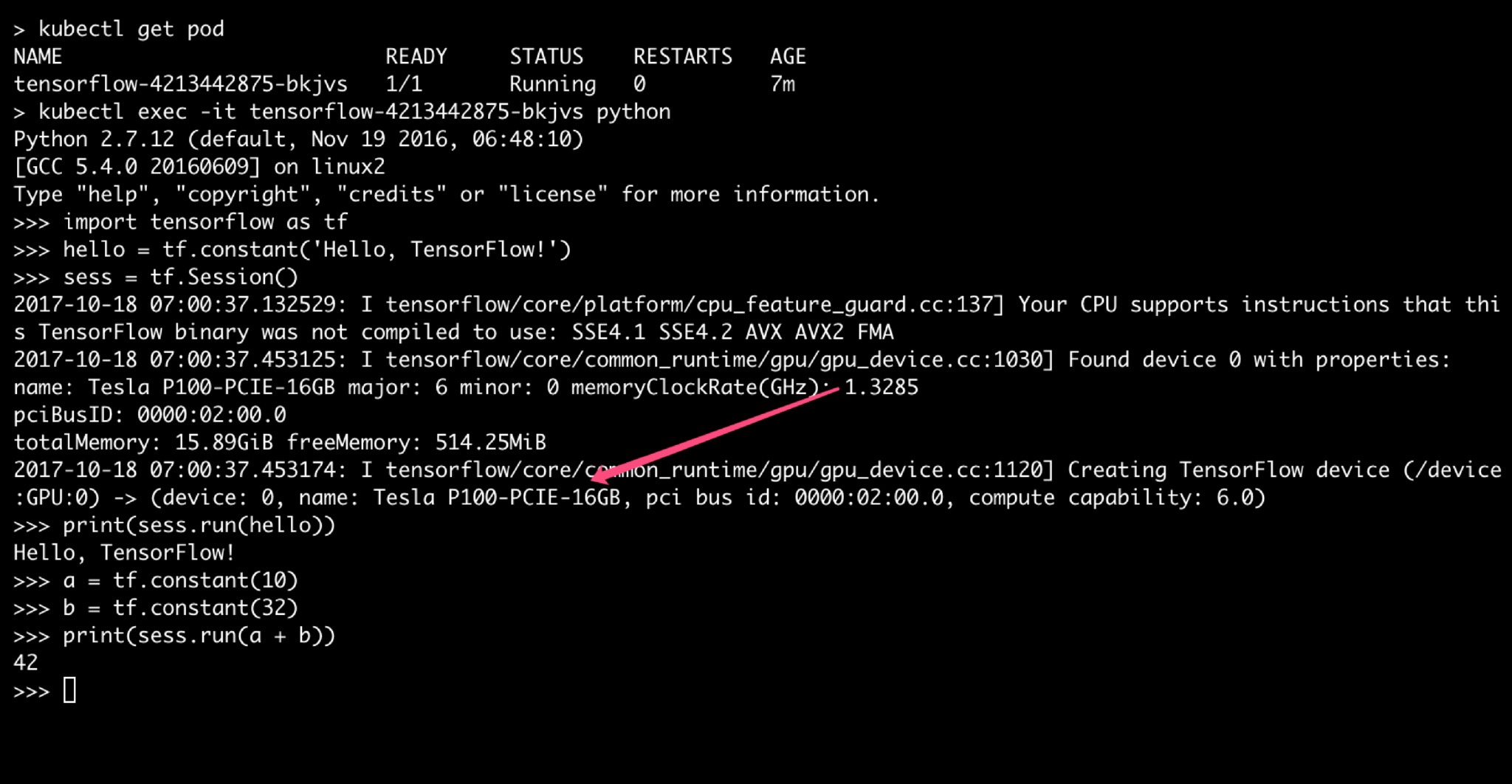
Pod 运行成功后可执行以下代码测试 GPU 调用
1 | |
成功后截图如下